
Mit einem hochkomplexen System kann Facebook mittlerweile in mehr als 100 Sprachen übersetzen. Und dies direkt von einer in die andere Sprache, ohne dabei in eine Referenzsprache übersetzen zu müssen. Das neue Übersetzungsmodell stellt Facebook als Open Source zur Verfügung!
Dass Facebook schon länger nicht nur eine blaue Kommunikationsplattform ist, dürfte mittlerweile vielen Menschen bekannt sein. Facebook arbeitet neben der Pflege und Wartung ihres eigenen Systems intensiv in Forschung und Entwicklung an unterschiedlichsten Themen rund um maschinelles Lernen, Augmented / Virtual Reality, an Internetverbindungstechnologien oder auch an Servermodellen und Computing-Plattformen. Nun stellt Facebook AI M2M-100 vor: Das erste mehrsprachige maschinelle Übersetzungsmodell (MMT), das zwischen einer beliebigen Kombination aus 100 verschiedenen Sprachen direkt übersetzen kann, ohne dafür auf die englische Referenzsprache angewiesen zu sein.
Es genügt ein einziger Klick auf den Text “Übersetzung anzeigen” unter einem Facebook-Beitrag oder -Kommentar, um den Inhalt in der bevorzugten Sprache anzuzeigen. Allein der Facebook-Newsfeed liefert Dank der leistungsstarken, mehrsprachigen und maschinellen Übersetzungstechnologie (MMT) der Social-Media-Plattform täglich 20 Milliarden solcher Übersetzungen.
Damit diese Übersetzung in Tausenden von Sprachen funktioniert, musste sich die MMT-Forschung bisher ausschliesslich auf englischsprachige Datensätze und Modelle stützen. Diese funktionieren im Normalfall so, dass die Ausgangssprache über eine Referenzsprache (Englisch) in die Zielsprache übersetzt wird. Heisst: Eine Übersetzung von Chinesisch zu Französisch erfolgt so, dass der chinesische Originaltext zuerst nach Englisch und dieser englischsprachige Text dann in die französische Version übersetzt wird. Was in den meisten Fällen gut funktioniert, aber dazu führt, dass Aussage und Bedeutung des Ursprungtextes vermindert werden.
Das von Facebook AI veröffentlichte Modell M2M-100 überspringt als erstes MMT-Modell diesen Zwischenschritt und kann direkt auf zwei Sprachpaardaten (Beispiel: Chinesisch-Französisch) trainiert werden. Es übertrifft damit klassische, englisch-basierte Systeme um ganze 10 Punkte auf der weit verbreiteten BLEU-Metrik (Bilingual Evaluation Understudy) zur Bewertung der Qualität maschineller Übersetzungen zwischen nicht-englischen Sprachen. Auch bei der Anzahl der Sprachrichtungen übertrifft Facebook mit M2M-100 alle bisherigen Modelle um den Faktor 10. Mit dem Training an insgesamt 2.200 Sprachrichtungen wird der Einsatz von M2M-100 die Qualität der Übersetzungen für Milliarden von Menschen verbessern, insbesondere für diejenigen, die wenig verbreitete Sprachen sprechen.
Maschinelle Übersetzung ist eine der wichtigsten Möglichkeiten, um Menschen zusammenzubringen, Sprachbarrieren zu brechen und Informationen allen verständlich und in ihrer Sprache zur Verfügung zu stellen. Bei durchschnittlich 20 Milliarden Beiträgen pro Tag im News-Feed von Facebook sind die bisherigen Modelle aber an ihre Grenzen gestossen. Denn: Typische MT-Systeme erfordern die Erstellung separater KI-Modelle für jede Sprache und jede Aufgabe. Dieser Ansatz liess sich auf Facebook nicht effektiv skalieren, wo Menschen Inhalte in mehr als 160 Sprachen in Milliarden von Beiträgen posten. Hochentwickelte mehrsprachige Systeme können zwar mehrere Sprachen gleichzeitig verarbeiten, gehen jedoch bei der Genauigkeit Kompromisse ein, indem sie sich auf englische Daten stützen, um die Kluft zwischen Quell- und Zielsprache ressourcenschonend zu überbrücken.
Dieser Ansatz reichte Facebook nicht. Mit der Erforschung und Entwicklung eines mehrsprachigen maschinelle Übersetzungsmodells, das jede beliebige Sprache direkt übersetzen kann. Mit einer neuartigen Methode zur Erstellung von Übersetzungsdaten, hat Facebook mit M2M-100 den ersten echten “Many-to-Many”-Datensatz mit 7,5 Milliarden Einträgen für 100 verschiedene Sprachen erstellt. Dabei wurden mehrere Skalierungstechniken eingesetzt, um ein universelles Modell mit insgesamt 15 Milliarden Parametern zu erstellen, das Informationen aus verwandten Sprachen erfasst und eine vielfältigere Schrift von Sprachen und Morphologie widerspiegelt. Facebook stellt diese Arbeit als Open Source zur Verfügung.
Eine der grössten Hürden beim Aufbau eines “Many-to-Many-MMT”-Modells ist das Kuratieren grosser Mengen qualitativ hochwertiger Satzpaare (auch als Parallelsätze bekannt) für beliebige Übersetzungsrichtungen, die nicht die englische Sprache betreffen. Es ist viel einfacher, Übersetzungen für Chinesisch in Englisch und Englisch in Französisch zu finden als beispielsweise Französisch in Chinesisch. Darüber hinaus wächst die für das Modell-Training erforderliche Datenmenge exponentiell mit der Anzahl der unterstützten Sprachen. Wenn zum Beispiel 10 Millionen Satzpaare für jede Richtung benötigt werden, dann müssen 1 Milliarde Satzpaare für 10 Sprachen und 100 Milliarden Satzpaare für 100 Sprachen gefunden werden.
Um diese Daten zu generieren, hat Facebook eine Kombination bereits bestehender Methoden, die seit Jahren in Arbeit sind, darunter ccAligned, ccMatrix und LASER, eingesetzt. Und dabei neben der Verbesserung der FastText-Sprachidentifizierung mit Laser 2.0 auch eine dieser Methoden weiterentwickelt, welche die Qualität des Mining verbessert und Open-Source-Trainings- und Bewertungsskripte umfasst. Alle Data-Mining-Ressourcen von Facebook nutzen öffentlich zugängliche Daten und stammen aus offenen Quellen.
Doch selbst mit fortschrittlichen zugrundeliegenden Technologien wie LASER 2.0 ist die Gewinnung umfangreicher Trainingsdaten für beliebige Paare von 100 verschiedenen Sprachen (oder 4.450 möglichen Sprachpaaren) sehr rechenintensiv. Daher hat Facebook Strategien entwickelt, um dem entgegenzuwirken:
Insgesamt verbesserte die Kombination aus der Brückenstrategie und rückübersetzten Daten die Leistung in den 100 rückübersetzten Sprachrichtungen um durchschnittlich 1,7 BLEU im Vergleich zum Training mit den ursprünglichen Übersetzungsdaten.
Ebenfalls fand Facebook beeindruckende Ergebnisse bei Zero-Shot-Einstellungen, bei denen für ein Sprachenpaar keine Trainingsdaten verfügbar sind. Wenn ein Modell zum Beispiel auf Französisch-Englisch und Deutsch-Schwedisch trainiert wird, kann Facebook eine Zero-Shot-Übersetzung zwischen Französisch und Schwedisch durchführen. In Situationen, in denen das Many-to-Many-Modell die Übersetzung zwischen nicht-englischen Richtungen “zero-shot” machen muss, war es wesentlich besser als englischzentrierte, mehrsprachige Modelle.
Eine Herausforderung bei der mehrsprachigen Übersetzung besteht darin, dass ein einzelnes Modell Informationen in vielen verschiedenen Sprachen und unterschiedlichen Schriften erfassen muss. Um diesem Problem zu begegnen, sah Facebook einen klaren Vorteil darin, die Kapazität des Modells zu skalieren und sprachspezifische Parameter hinzuzufügen. Die Skalierung der Modellgrösse ist insbesondere für ressourcenintensive Sprachpaare hilfreich, da sie über die meisten Daten verfügen, um die zusätzliche Modellkapazität zu trainieren. Letztendlich sah Facebook bei einer dichten Skalierung der Modellgrösse auf 12 Milliarden Parameter eine durchschnittliche Verbesserung von 1,2 BLEU über alle Sprachrichtungen hinweg, woraufhin die Erträge aus der weiteren dichten Skalierung abnahmen. Die Kombination aus dichter Skalierung und sprachspezifisch spärlichen Parametern (3,2 Milliarden) ermöglichte es Facebook, ein noch besseres Modell mit insgesamt 15,4 Milliarden Parametern zu erstellen.
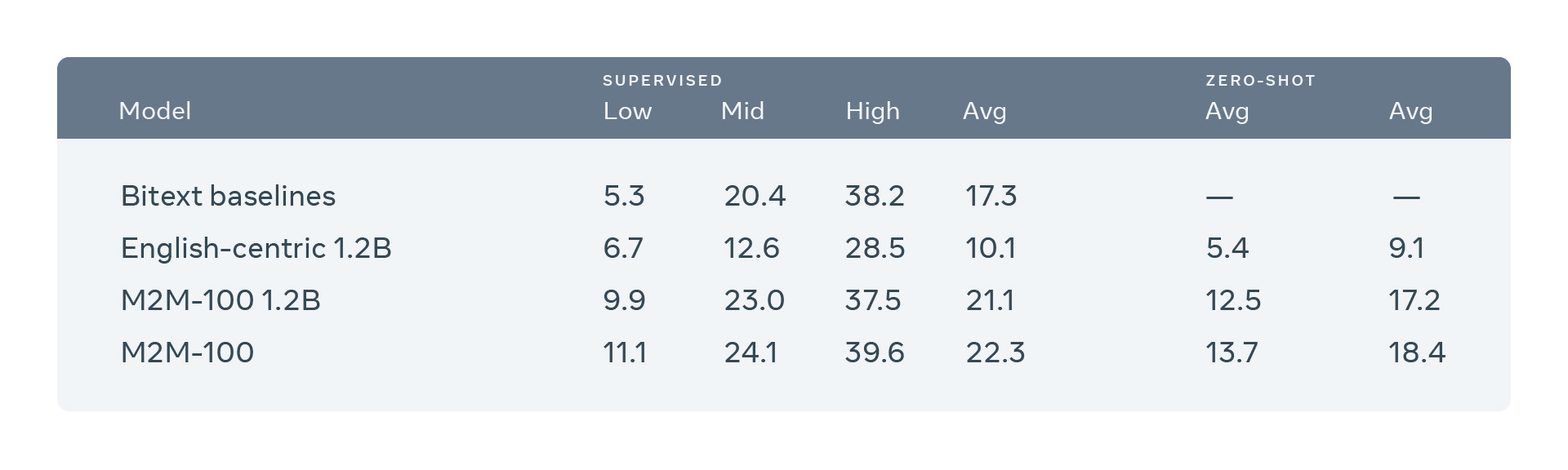
Facebook Parameter-Tabelle
Da nicht jeder Forscher die Möglichkeit hat, Modelle auf Hunderten von GPUs zu trainieren, hat Facebook das Modell inklusive aller Trainingsdaten und Parameter öffentlich zur Verfügung gestellt. Damit ermöglicht Facebook anderen Forschern und Entwicklern, eigene und verbesserte Übersetzungstools einer breiteren Basis zur Verfügung zu stellen.
Auch wenn diese Thematik wenig mit den üblicherweise hier publizierten Beiträgen zu tun hat, ist es doch eindrücklich zu sehen, in welchen Komplexitäten Facebook Forschung und Entwicklung betreibt. Das vorgestellte Modell und die weiteren Übersetzungstools von Facebook werden Schlüsselrollen bei der Entwicklung eines einzigen Modells spielen, das alle Sprachen und Dialekte versteht. Und ein solches Modell verringert die Sprachbarrieren immens, stellt Informationen für mehr Menschen zur Verfügung und ermöglicht eine einfache grenzüberschreitende Kommunikation. Es ist schön zu sehen, dass die Arbeit sowie die darüber erzielten Fortschritte von Facebook veröffentlicht und somit die Bedeutung dieser und weiterer Entwicklungen untermauert wird.
Autor: Thomas Hutter | 2032 Posts
Thomas Hutter ist Inhaber und Geschäftsführer der Hutter Consult AG. Er ist als einer der renommiertesten Facebook Marketing und Social Media Experten im deutschsprachigen Raum bekannt und wird gerne auch in den Medien als "Facebook Guru" oder "Facebook Papst" tituliert. Mit seinem Team berät er grosse und mittelständische Unternehmen, Organisationen sowie Agenturen in und rund um Facebook und Social Media Marketing. Mit seinem Blog "www.thomashutter.com" legte er 2009 den Grundstein der Hutter Consult AG. Sein Blog gilt nach wie vor als eine der wichtigsten Ressourcen zu aktuellen Entwicklungen im Bereich Facebook und Social Media Marketing. Sein umfangreiches Wissen trägt er als Dozent an Fachhochschulen und als Referent in der DACH-Region an Teilnehmer weiter. Man trifft ihn auf Branchen-Konferenzen als Speaker und Mentor hautnah, live und in Farbe.





