
Das KI-Team von LinkedIn hat einige Einblicke in das Modell des qualifizierten Bewerbers auf LinkedIn gewährt. Mit personalisierter KI sollen die Vorlieben für Jobsuchende und Jobanbieter ermittelt und direkt den betroffenen Personen eingeblendet werden.
Die Vision von LinkedIn ist es, ökonomische Chancen für alle Mitglieder des globalen Arbeitsmarktes zu schaffen. Der Schlüssel dazu liegt darin, den Markt zwischen Arbeitssuchenden und Arbeitgebern effizienter zu gestalten. Aktive Arbeitssuchende bewerben sich oft für viele Jobs und erhalten aber nur von den wenigsten Rückmeldungen. Gleichzeitig werden Arbeitgebende mit Bewerbungen überflutet. Die Zeit für die Überprüfung ist häufig begrenzt. Das führt dazu, dass qualifizierte Kandidaten übersehen werden. Diese Ineffizienz frustriert beide Seiten.
Um diese Probleme konkret anzugehen, hat LinkedIn ein KI-Modell für qualifizierte Bewerber (QB) entwickelt. Das Modell wird mit den Fähigkeiten und Erfahrungen eines Bewerbers trainiert, welche ein Arbeitgeber sucht. Dies geschieht auf der Grundlage des Engagements des Job-Anbieters mit früheren Bewerbern. LinkedIn verwendet das Modell, um den LinkedIn Mitgliedern dabei zu helfen, Jobs zu finden, für die sie die beste Chance haben. Zudem auch um eine Antwort zu erhalten und um die Wahrscheinlichkeit zu verringern, dass die Job-Anbieter vielversprechende Bewerber übersehen. Deshalb hebt LinkedIn diejenigen Stellen hervor, die gut zu einem LinkedIn Mitglied passen.
Bei der Umsetzung des Modells gibt es mehrere Herausforderungen. Eine davon ist die Entwicklung eines Modells, das für alle Arbeitssuchenden und Arbeitgebende mit “Modellpersonalisierung” effektiv ist. Zum anderen muss anerkannt werden, dass die individuelle Arbeitssuche und die Stellenausschreibungen vergänglich sind und dass ein personalisiertes Modell veralten kann, wenn es nicht regelmäßig aktualisiert wird. Eine weitere Herausforderung ist der Umfang, in dem personalisierte Modelle trainiert werden müssen. Das QB-Modell hat Milliarden von Koeffizienten und daher ist die Skalierbarkeit des KI-Modells von grösster Bedeutung.
LinkedIn zeigt mit einem eingehenden Blick auf die Trainingsdaten, Personalisierung, Skalierbarkeit, Service-Infrastruktur, etc., wie sie die Herausforderungen gemeistert haben. Das LinkedIn-Team hat auch wichtige Erkenntnisse darüber erhalten, was wichtig ist, um ein solches System erfolgreich zu machen.
Das KI-Modell zielt darauf ab, vorherzusagen, wie wahrscheinlich es ist, dass ein Mitglied kontaktiert wird, wenn es sich für eine bestimmte Stelle bewirbt. Formal versucht LinkedIn die Wahrscheinlichkeit einer positiven Recruiter-Aktion vorherzusagen, die davon abhängt, dass sich ein bestimmtes Mitglied auf eine bestimmte Stelle bewirbt.
Qualifizierte Bewerber Formel (Quelle: LinkedIn)
Was eine positive Recruiter-Aktion ausmacht, hängt vom spezifischen Kontext ab. Dazu kann beispielsweise gehören, dass das Profil eines Bewerbers eingesehen wird, eine Nachricht an den Bewerber gesendet wird, dass er zu einem Vorstellungsgespräch eingeladen wird oder ihm schlussendlich ein Stellenangebot offeriert wird.
Personalisierung ist der Versuch, Aktionen vorherzusagen und Produkterlebnisse zu schaffen, die auf den einzelnen Benutzer zugeschnitten sind. Während die Personalisierung regelbasiert sein kann, sind Ansätze des maschinellen Lernens effektiver, wenn genügend Daten zur Verfügung stehen. Da der LinkedIn-Arbeitsmarkt jedoch groß und vielfältig ist, kann ein einziges (globales), maschinelles Lernmodell suboptimal sein, um einzigartige Besonderheiten zu erfassen.
In solchen Fällen passt LinkedIn das globale Modell individuell für jedes Mitglied und jede Stelle an. Dies wird mit dem jeweiligen Modell für das Mitglied und für die Stelle ermöglicht.
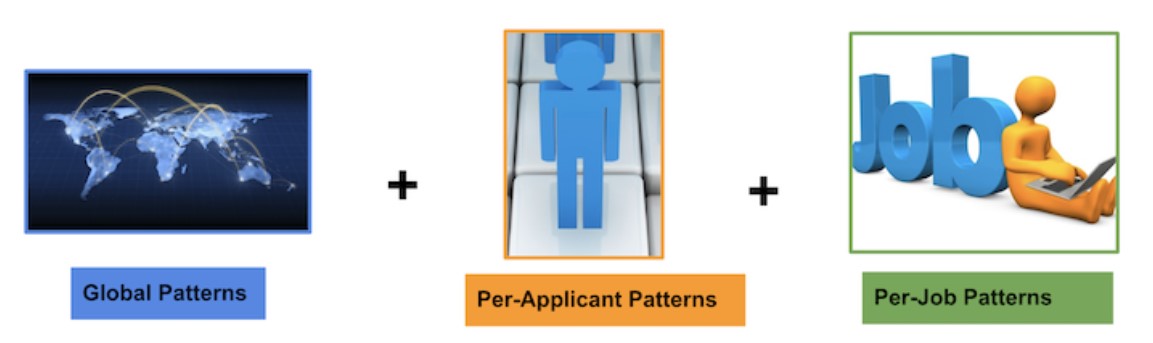
Zusammensetzung des Modells (Quelle: LinkedIn)
Mathematisch kann diese Zusammensetzung des Modells etwa so aussehen:
Mathematische Herleitung des Modells (Quelle: LinkedIn)
Wo Xm und Xj Mitglieder sowie Job-Optionen Vektoren sind, ist f(global) ein Globalmodell. Fm (xj) ist ein Modell pro Mitglied, das mit den Jobs trainiert wird, auf welche sich ein Mitglied bewirbt. Fj (Xm) ist ein Modell pro Stelle, welches mit den Mitgliedern trainiert wird, die mit der Jobausschreibung interagiert haben. Das Modell gehört zur Klasse der verallgemeinerten additiven Mischmodelle.
LinkedIn verwendet lineare Modelle für fm und fj, aber jedes Modell kann in die obige Formulierung eingesetzt werden, solange die produzierten Scores auf die Ausgabe von log-odds (z.B. ein neuronales Netz) kalibriert sind. Gewöhnlich sind lineare Modelle als Komponenten pro Mitglied und pro Stelle ausreichend, da einzelne Mitglieder und einzelne Stellen nicht genügend Interaktionen haben, um komplexere, nicht-lineare Modelle zu trainieren.
Die drei Komponenten – global, pro Mitglied und pro Stelle – werden in einem Loop trainiert (unter Verwendung von Photon ML und dem folgenden Algorithmus). Jedes der Pro-Mitglieder-Modelle und Pro-Stellen-Modelle ist innerhalb einer einzigen Trainingsiteration unabhängig voneinander, abhängig von den Punktzahlen, die von anderen Komponenten produziert werden, wodurch jede Iteration parallel und daher leicht zu verteilen ist.
Während das globale Modell auf allen Daten trainiert wird, wird jedes Modell pro Mitglied nur mit den jüngsten Bewerbungen des Mitglieds und jedes Modell pro Stelle mit den jüngsten Bewerbungen dieser Stelle trainiert. Für den Arbeitsansatz von LinkedIn ist es wichtig, eine ausreichende Datendichte über Mitglieder und Stellen zu haben.
Die Analyse von LinkedIn hat gezeigt, dass sich die Mehrheit der Bewerber auf mindestens fünf Stellen bewirbt, während die Mehrheit der Stellenausschreibungen mindestens zehn Bewerbungen erhält. Daraus ergeben sich genügend Daten, um die Personalisierungsmodelle zu trainieren.
Das personalisierte QB-Modell verbesserte die Offline-Evaluationsmetrik, die Fläche unter der ROC-Kurve (AUC), um +27%. LinkedIn beobachtet ähnliche Verbesserungen bei den NDCG-Metriken (normalisierter diskontierter kumulativer Gewinn). Die Ausgangsbasis des LinkedIn KI-Teams war das zuvor eingesetzte Baummodell mit Gradientenverstärker, das auf demselben Datensatz und denselben Merkmalen trainiert wurde. LinkedIn schätzt auch, dass der Beitrag von Modellen pro Mitglied und pro Stelle je nach Anwendungsfall stark variiert. Das bedeutet, dass bei einigen Datensätzen Modelle pro Mitglied für den größten Teil des Gewinns verantwortlich und bei einigen Datensätzen Modelle pro Stelle wichtiger sind.
Modelle, die mit Hochgeschwindigkeitsdaten trainiert wurden, können schnell veralten und erfordern möglicherweise häufige Anpassungen. Dies ist bei den Personalisierungskomponenten des QB-Modells (qualifizierte Bewerber) der Fall, die auf das Engagement von Recruitern trainiert werden. Tatsächlich halbiert sich der Vorteil für ein pro Mitglied personalisiertes Modell nach nur drei Wochen ohne Aktualisierungen gegenüber dem Basismodell. Bei der Personalisierung von Modellen pro Stelle ist dieser Verfall sogar noch schneller.
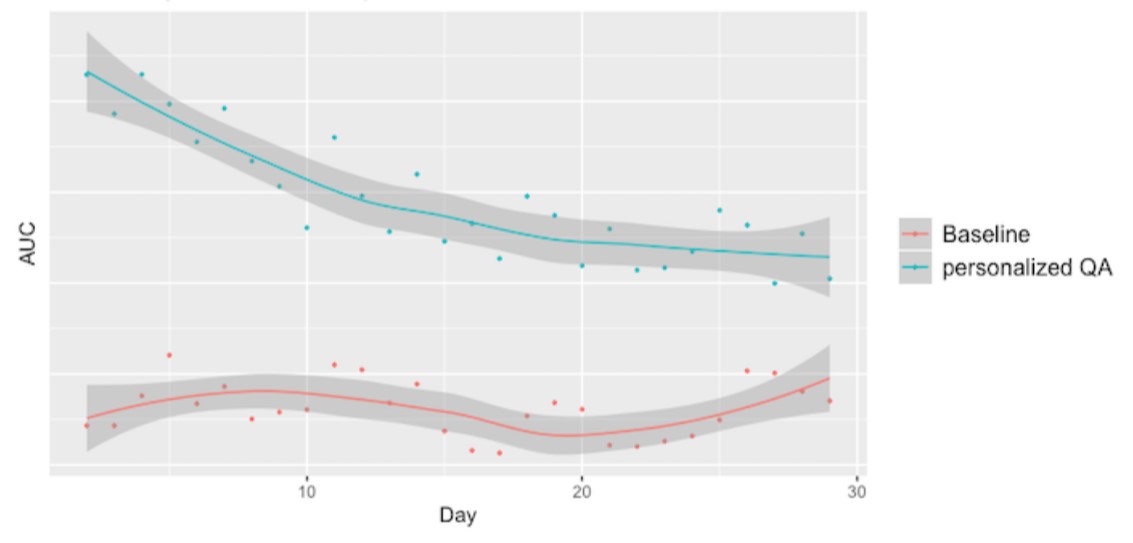
Zerfall der AUC-Metrik in einem personalisierten QB-Modell (blaugrün) im Vergleich zu einer Basislinie (rot), wenn das personalisierte Modell nicht aktiviert wird (Quelle: LinkedIn)
Häufige Aktualisierungen sind notwendig, um den höchstmöglichen Leistungsgewinn gegenüber dem Basismodell aufrechtzuerhalten. Dies ist zu erwarten, da die Basislinie globale Datenmuster lernt und sich nicht mit der Zeit verschlechtert. Allerdings können einzelne Bewerber nur mehrere Wochen aktiv auf Stellensuche sein. Neue Stellen können innerhalb von Wochen oder sogar Tagen besetzt werden. LinkedIn hat ein sehr kurzes Zeitfenster, in dem sie die Muster pro Mitglied und pro Stelle lernen und nutzen können, solange sie noch aktiv sind.
Um dem Zerfall entgegenzuwirken, muss LinkedIn die Modellkomponenten pro Mitglied und pro Stelle häufig aktualisieren. Das globale Modell bedarf keiner häufigen Aktualisierung. Jeden Tag erstellt LinkedIn neue Trainings-Labels, welche die Modell-Komponenten pro Mitglied und pro Stelle automatisch neu anlernen und setzen sie in der Produktion ein.
Jeden Tag engagieren sich die Arbeitgeber mit neuen Kandidaten. LinkedIns Pipeline greift diese Ereignisse auf, um neue Trainings-Labels zu schaffen. Im Idealfall soll dies schnellstmöglich umgesetzt werden, um die Latenzzeit zu verkürzen, mit der neue Informationen in das Modell eingearbeitet werden. In der Praxis muss das KI-Team jedoch warten, bis sich entweder ein Job-Anbieter mit einem Kandidaten einlässt (Positiv-Etikett) oder das Team muss eine willkürliche Zeitspanne abwarten, bevor es auf ein Negativ-Etikett schließen kann. Ein Ansatz besteht darin, nach einer Bewerbung einige Zeit zu warten (z.B. zwei Wochen) und sie dann auf der Grundlage des vorhandenen Engagements als positiv oder negativ zu kennzeichnen. Dies ist zwar einfach, aber eine solch lange Wartezeit wirkt sich aufgrund der Geschwindigkeit, mit der diese Daten an Aktualität verlieren, negativ auf die Leistung des QB-Modells aus. Auf der Grundlage der Analyse einer typischen Recruiter-Aktion ist LinkedIn jedoch in der Lage, viele der positiven Feedbacks viel früher zu identifizieren – 30 % werden innerhalb eines Tages erkannt.
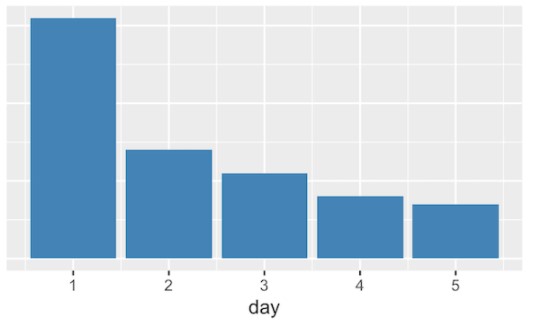
Übersicht der Wahrscheinlichkeit eine positive Zusage zu erhalten
Die obige Grafik zeigt den Anteil an Bewerbern, die an einem bestimmten Tag nach der Einreichung der Dossiers ihre positive Zusage erhalten haben. Die Wahrscheinlichkeit einer Zusage ist am ersten Tag am höchsten und sinkt bald danach.
LinkedIn hat eine schnelle Label-Kollektions-Pipeline implementiert. Die Pipeline enthält alle positiven und negativen Feedbacks sobald diese verfügbar sind, während negative Rückmeldungen auf der Grundlage des Kontexts der Stellenausschreibung heuristisch hergeleitet werden. Wenn ein Recruiter anderen Bewerbenden später Feedback gibt, geht LinkedIn davon aus, dass es eine negative Rückmeldung mit keinem Engagement für die Applikation gegeben hat.
LinkedIn hat definiert, dass ein negatives Feedback festgehalten wird, wenn nach 14 Tagen kein Engagement zu erkennen ist. Das bedeutet, dass LinkedIn das QB-Modell auf eine immer bessere Annäherung des Datensatzes trainieren kann.
Die oben beschriebene Pipeline arbeitet offline mit Batch-Training. Es dauert bis zu einem Tag, um neue Labels zu generieren, die personalisierten Modellkomponenten zu aktualisieren und neu zu verteilen.
Die technische Vision des KI-Teams ist es, dies von Stunden auf Minuten zu reduzieren. LinkedIn entwickelt eine Pipeline für die Datenerfassung und für das Training nahezu in Echtzeit, die mit Stream-Verarbeitungstechnologien wie Apache Samza und Apache Kafka aufgebaut werden. Dieses System aggregiert die jüngsten Interaktionen, um einzelne personalisierte Modellkomponenten asynchron zu trainieren und zu aktualisieren. Anstelle einer Latenzzeit von Stunden für die Aktualisierung der QB-ähnlichen Modelle, wird dies effiziente datengesteuerte Aktualisierungen innerhalb von Minuten ermöglichen.
Die personalisierten Modellkomponenten müssen täglich parallel trainiert werden, was zu Milliarden von Koeffizienten führt, die auf Hadoop HDFS gespeichert sind. Um das Modell online anbieten zu können, stellt LinkedIn das Modell in einem Online-Dienst zur Verfügung. Während das globale Modell klein genug ist, um in den Speicher eines einzelnen Servers zu passen, ist die kumulierte Summe der personalisierten Komponenten dafür viel zu groß. LinkedIn kann zum Glück die Modellstruktur nutzen, um die Speicherung zu parallelisieren und nur die Teilmenge der Koeffizienten abzurufen, die für die Bewertung einer bestimmten Anfrage erforderlich sind.
LinkedIn speichert Modellkoeffizienten pro Mitglied und pro Stelle in Venedig IT, dem verteilten Online-Schlüsselwertspeicher von LinkedIn. Bei einer typischen Anfrage werden die QB-Punktzahlen für ein einzelnes Mitglied und eine Reihe von Stellen oder für eine Stelle und mehrere Mitglieder berechnet. Relevante Personalisierungskoeffizienten können mit einer einzigen Stapelabfrage beim Schlüsselwertspeicher abgerufen werden. Zudem werden sie vom Online-Dienst zwischengespeichert. Zusammen mit dem globalen Modell, das permanent im Speicher des Dienstes gehalten wird, werden diese für das Scoring verwendet.
Um das QB-Modell auf dem neuesten Stand zu halten, trainiert das KI-Team es täglich mit neu gesammelten Engagement-Daten. Wenn das aktualisierte Modell automatisierte Qualitätsprüfungen besteht (z.B. bessere Bewertungsmetriken für den Validierungssatz im Vergleich zum Modell aus den vorherigen Trainings), aktualisiert LinkedIn die Koeffizienten im Schlüsselwertspeicher. Um die Trainingszeit zu verkürzen, initialisiert die Plattform die Koeffizienten mit ihren aktuellen Werten und aktualisieren sie selektiv. Da sich das globale Modell beispielsweise nicht so schnell ändert wie das Modell pro Mitglied aktiver Arbeitssuchender, werden die globalen Koeffizienten nur alle paar Wochen neu trainiert.
Die Komponenten des Systems sind im folgenden Diagramm aufgezeigt:
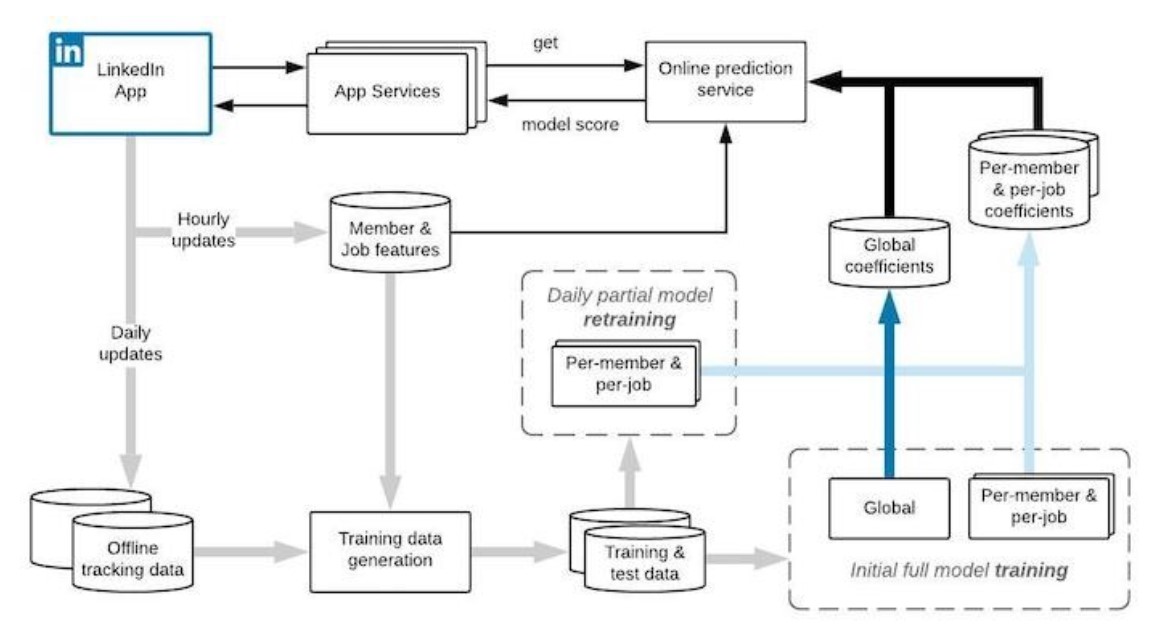
Systemdesign und Infrastruktur des QB-Modells zusammengefasst mit Offline-Trainings, täglicher Aktualisierung und Online-Dienst Komponenten (Quelle: LinkedIn)
LinkedIn hat das Modell für die Premium Accounts, für die Recuiter-Nutzer und für die Jobsuchenden eingerichtet. In allen drei Bereichen teilte LinkedIn mit, dass es signifikante Verbesserungen der Kennzahlen gab. Auf der Seite der Stellensuchenden hebt LinkedIn die Ergebnisse von Stellen hervor, wenn das Profil eines Mitglieds gut zu der Stelle passt (Produkt Quality Match). Für Premium-Mitglieder stellt LinkedIn zusätzlich Stellen vor, für die das Mitglied wettbewerbsfähiger wäre als die anderen Bewerber (Produkt Top-Bewerber). Job-Anbieter, die LinkedIn Recruiter verwenden, profitieren schließlich von einer intelligenteren Einstufung der Bewerber und erhalten Benachrichtigungen, wenn sich Mitglieder mit einem sehr hohen Match-Ergebnis auf ihre Stellen bewerben.

Benachrichtigung für den Recuiter (Quelle: LinkedIn)
LinkedIn verwendet das personalisierte QB-Modell im Anwendungsfall des Recuiter, um Bewerber im Recuiter-System zu bewerten. Das neue QB-Modell führte zu zweistelligen Zuwächsen bei der Interaktionsrate der Job-Anbieter, z.B. beim Herunterladen von Lebensläufen und bei der positiven Rekrutierungsrate. LinkedIn verwendet das neue Modell auch, um den Job-Anbietern selektiv eine Benachrichtigung zu senden, wenn sich ein qualifizierter Bewerber bewirbt, was zu einer zweistelligen Steigerung der Klickrate (CTR) für diese Benachrichtigungen führte.

Vorgeschlagene Stellen für Arbeitssuchende (Quelle: LinkedIn)
Für den Anwendungsfall Arbeitssuchende verwendet LinkedIn ebenfalls das QB-Modell, um Stellen hervorzuheben, für die ein Mitglied sehr qualifiziert ist. Dies führte zu einem Anstieg der bestätigten Einstellungen, die sowohl auf der Seite der Arbeitgeber als auch auf der Seite der Arbeitssuchenden eine qualitative Übereinstimmung zeigen.
Jobvorschläge für die Premium-Mitglieder (Quelle: LinkedIn)
Im Anwendungsfall Premium gibt LinkedIn den Premium-Mitgliedern Einblicke in ihre eigene Einstufung im Vergleich zu anderen Bewerbern auf der Grundlage des QB-Vorhersagewertes. In diesem Anwendungsfall konnte die CTR für Premium-Arbeitssuchende verbessert werden.
Mit dem QB-Modell werden Stellenausschreibungen, die auf LinkedIn publiziert werden, potenziellen Kandidaten besser vorgeschlagen als zuvor. Denn LinkedIn stimmt nicht nur die Anforderungen mit den hinterlegten Kenntnissen im Profil, sondern auch an den Engagements seitens Arbeitssuchenden und Recuiter ab. Damit jedoch maschinelles Lernen effektiv ist, müssen genügend Datensätze vorhanden sein, was für jedes Individuum nur schwierig ist. Das Modell ist sicherlich eine unglaubliche Steigerung hinsichtlich des Unterstützungsfaktors für Jobsuchende und Jobanbieter. Jedoch darf nicht vergessen werden, dass solche Vorschläge von LinkedIn beispielsweise für einen Quereinsteiger nicht wirklich relevant sein können. Die künstliche Intelligenz unterstützt die Recruiter, aber auch die Arbeitssuchenden in ihrem Prozess. Jedoch dürfen beide Seiten sich nicht zu 100% darauf verlassen und nur noch solche Vorschläge berücksichtigen. Wir sind gespannt, wie sich das KI-Modell von LinkedIn weiterhin entwickelt und was es zukünftig für neue Features gibt.
Autor: Belinda Weibel | 53 Posts
Belinda Weibel war bis November 2022 Consultant Digital Marketing bei der Hutter Consult AG.





